TL;DR
- Cloud risk is rising faster than readiness. Based on Thales Cloud Security Study 2025, 64% of enterprises now treat cloud security as a top priority, but only 8% encrypt even 80% of their sensitive data. With 54% of cloud data now classified as sensitive and AI-related threats consuming budget, most teams are falling behind on foundational controls.
- Tool sprawl is breaking SDLC security. Most orgs still rely on siloed application security testing tools for source, build, registry, and runtime. Without a unified graph, they can’t trace risk across environments or attribute issues to the teams and changes that caused them.
- Identity-first controls are now table stakes. CI jobs, bots, and cloud workloads act as privileged users. Without scoped, short-lived identities and JIT access, one misconfigured pipeline can expose prod-wide blast radius, still a top root cause of cross-env incidents.
- Building provenance is rarely enforced. SBOMs and PBOMs are generated by SBOM tools, but deploy gates still allow unsigned or unverifiable artifacts, especially in hotfix paths. Without policy enforcement, trust remains an assumption, not a check.
- Governance must shift from manual to systemic. Compliance and audit trails can’t depend on exports and reviews. Platforms like Ox embed policy, ownership, and evidence into every deploy, making governance a built-in outcome, not a bolt-on process.
Cloud-native architecture, microservices, containers, IaC, ephemeral compute, and now AI-assisted development have reshaped how platforms are built and operated. Teams ship faster, scale dynamically, and rely on distributed infrastructure. That’s good for agility, but the exposure footprint we now have to protect is not just broader, it’s more fragmented, more automated, and in many cases, less visible
Enterprise security teams are under pressure to secure this moving target, and the pressure is real and immediate. According to the Thales Cloud Security Study 2025, 64% of enterprises now view cloud security as a top-priority discipline, but only 8% of them encrypt 80% or more of their cloud data. At the same time, 54% of cloud data is classified as sensitive, and that share is rising. Meanwhile, AI is reshaping the threat landscape and the budget: over half of surveyed organizations say AI-related security is now cutting into or taking over their existing budgets.
This reflects what we see across the board: a growing mismatch between risk and readiness. Most platforms today are stitched together from multiple pipelines, registries, cloud accounts, and runtime environments, each with its own tools, rules, and blind spots. Traditional security models, isolated scanners, post-deploy audits, and rigid gateways don’t provide the kind of traceability or response speed that these environments demand.
What’s needed is a model that connects all the dots: code commits, build artifacts, container images, cloud assets, and runtime behavior, one graph, not 10 tools. That’s the direction enterprise teams are heading. Platforms like Ox Security are leading this shift, providing unified code-to-runtime security posture and helping teams answer the right questions early: Where did this vulnerability originate? Is it exploitable? Who owns it?
Security at this scale has to be in real-time, contextual, and built into the software delivery lifecycle, not bolted on after the fact.
Why Cloud-Native Security Requires a Unified View in 2026
Heading into 2026, the operational reality of platform security is shifting fast. Most enterprises aren’t just running containerized workloads across multiple clouds; they’re shipping AI-assisted code, deploying autonomous agents, and handling sensitive data through more external services than ever before. The architecture is now multi-layered, fast-moving, and largely invisible unless you’ve instrumented for it.
Google’s Cybersecurity Forecast 2026 reinforces this trajectory. It highlights how adversaries will use AI to scale attacks and blend into normal activity. It also points out how enterprise teams are introducing new attack paths through AI agents and “invisible” pipelines that don’t show up in traditional logs or scanners.
Visibility Gaps in Cloud-Native Pipelines: Why Correlation Across the SDLC Is Important
What this means in practical terms: you can’t secure what you can’t correlate.
Most teams still rely on separate tools for scanning code, containers, cloud configs, and runtime. But when a container in prod shows anomalous behavior, say, a suspicious process or API call, they can’t trace it back to the original repo, the exact build that generated it, or the pull request that introduced the problem. They see the symptom, not the cause.
In 2026, this gap becomes more than a workflow issue; it becomes a threat plane. AI agents running in production may not use human credentials. Model prompts could trigger external API calls. Compromised workloads could spread laterally in minutes. If you can’t map all those events back to their origin and do it automatically, your response is reactive at best.
Platform Security Now Demands End-to-End Context: From Git to Runtime
To manage risk at this scale, platform teams need to treat the entire software lifecycle, from code to build to container to runtime, as one connected graph. That graph should show:
- where every artifact came from,
- how it was built,
- where it’s running, and
- What it’s doing now.
This is about having a system of record that ties everything together.
Best Cloud-Native Security Practices: From IaC and Pipelines to Runtime Controls and Audit Evidence
Security architecture only scales when controls and practices scale alongside the cloud footprint. In fact, most of the operational friction we see in cloud-native environments comes from teams bolting on more tools instead of enforcing consistent practices across the software lifecycle. You can’t manage risk by adding dashboards. You need a posture that’s embedded in how your platform runs, across code, build, deploy, and runtime.
Below are the best practices that anchor a defensible, operationally manageable security posture in an enterprise environment.
A. Enforce Identity-First Controls
In cloud-native platforms, identity is the only reliable perimeter. Every actor, whether a workload, a CI job, a developer, or a third-party tool, is just another identity making API calls. If you haven’t defined who can do what, for how long, and under which conditions, then you’re leaving the door open.
The biggest security failures I’ve seen in cloud configs don’t come from missing controls; they come from unscoped or unaccountable identities. Pipelines running with production-wide permissions. Bots are using long-lived tokens issued months ago. Workloads silently call internal APIs with blanket credentials. Most teams don’t notice until something breaks or someone breaks in.
Here’s how we’ve addressed this pattern in high-scale environments, and what to watch for.
1. Replace shared or long-lived credentials
The first step is to kill static credentials. No tokens stored in CI secrets, no long-lived keys passed to containers. Every workload or job should get a short-lived identity issued at runtime, and only for the resources it needs.
On AWS, that’s IRSA for EKS workloads and OIDC for GitHub Actions. On GCP, it’s Workload Identity. On Azure, it’s a User-Assigned Managed Identity. All of them let you get rid of static access by using federated tokens. Your pods, jobs, and pipelines should be asking the platform for credentials as needed, and those credentials should auto-expire.
2. Scope permissions tightly, by role and by environment
Never let a dev-stage pipeline deploy to prod. Never let an app identity read secrets it doesn’t need. This sounds obvious, but most identity setups fail here; they grant admin or write-level access across environments because it’s easier to get things working that way.
Instead, create IAM roles per environment and per use case. For example:
- tf-deployer-staging for Terraform jobs that write to staging infra
- image-pusher-prod for pipelines that push validated images to the production registry
- read-metrics-app for services that only need to fetch Prometheus metrics
Bind each identity strictly to its scope. If a pipeline identity for dev tries to touch prod resources, the action should fail and alert.
3. Require Just-in-Time (JIT) elevation for admin actions
No engineer, bot, or job should have standing admin access. If someone needs to rotate a production secret or reconfigure an internal CA, they should request access, get it for 15–30 minutes, and lose it automatically afterward. This works best with services like Azure PIM, GCP Access Approval, or custom workflows that write into IAM conditions.
The point is simple: no privilege without a time window and a reason. This also gives you a clear audit trail for sensitive changes.
4. Make identity usage observable
You should be able to answer, within 30 seconds, who did what in any environment. That means every API call, resource mutation, or artifact deployment should tie back to:
- the actor’s identity (user, job, workload),
- the time and origin of the request,
- the change it introduced,
- and whether that action was expected.
Audit logs from AWS CloudTrail, GCP Audit Logs, or Azure Activity Logs should be wired into your detection pipeline, with alerts on things like:
- pipeline identity calling APIs outside its environment,
- same token reused across two clusters,
- identity performing a new, never-before-seen class of action.
5. Enforce identity presence through policy
This is where most of the friction comes in, but also where the platform gets more secure by default.
If a deployment doesn’t specify a valid service account, it should be rejected. If a CI job tries to run without requesting a federated token, it should fail. Use OPA (Gatekeeper), Kyverno, or platform-native controls to encode these rules at the infrastructure level. Security here isn’t optional; it’s enforced at deployment time.
What happens when CI pipelines share privileged identities
In one audit I ran, a CI job used a shared service account with admin access to all environments. A misconfigured script deleted key infra modules in staging. Nobody knew who triggered the job, because everything ran under the same opaque identity.
The fix: we issued one workload identity per pipeline per environment, each mapped to a minimal-permission IAM role. A merge policy required approval for sensitive Terraform modules, and CI logs were tied directly to the issuing identity. Now, every deployment is attributable, scoped, and time-bounded.
B. Enforce Signed Build Artifacts and Restrict Registries to Verified Sources
If you can’t trace where an image came from or who built it, you’ve already lost control of what’s running in production. An image built locally, pushed to a shared registry, tagged manually, and deployed without any checks is a risk that shows up after something breaks, not before.
Every artifact that enters your pipeline should be signed and tied to the exact commit and job that built it. If the signature is missing or the image came from a registry you don’t control, the deploy should fail.
In an EKS cluster running the internal developer platform, every image was pinned by digest and matched against a build record. If someone tried to deploy an unsigned hotfix or push a manual image to staging, it failed immediately; the platform simply didn’t run what it couldn’t verify.
At a minimum:
- Sign every artifact at build time and store the record
- Verify the image digest and signature before deploying
- Only allow registries you control, no tag-based pulls in production
Unverifiable code should never reach production, no matter how urgent the change is.
C. Restrict Ingress and Runtime Network Exposure
Once a workload is deployed, its network exposure defines the blast radius. If your platform doesn’t tightly control how services are exposed, or doesn’t log and enforce what’s talking to what, then any compromised pod, misconfigured ingress, or privilege escalation becomes a lateral movement opportunity.
This isn’t about microsegmentation for the sake of it. It’s about avoiding production workloads from becoming pivot points.
Start by locking down ingress. Any workload with a public-facing endpoint must have a defined ingress path through an API gateway, load balancer, or service mesh entry, with authentication and request validation. Ad-hoc NodePort or external LoadBalancer services should be banned by default unless explicitly reviewed.
Internally, workloads shouldn’t talk to each other without permission. That means defining default-deny network policies and explicitly allowing service-to-service communication where needed. In Kubernetes, this means writing NetworkPolicies per namespace or workload group, or using a mesh like Istio or Linkerd with intent-based access controls. In VPC-native environments, restrict traffic with security groups, NSGs, or firewall rules scoped to service identities, not just IPs.
From experience, the most dangerous exposure paths aren’t obvious. A common pattern: a staging app with open ingress pulls secrets from a shared internal API, and that API doesn’t validate the source identity. Or a pod in a dev cluster can reach the internal control plane of a monitoring service, simply because no deny rule was ever written.
One team I worked with had a pod in staging that was compromised through a vulnerable debug endpoint. The attacker didn’t go after production directly; they pivoted from staging to hit a shared image registry used by both environments. Why? Because there were no internal egress controls, and the registry didn’t validate the origin network. That alone let them poison images that later made it to production.
To avoid this:
- Start from a default-deny posture with container security solutions for both ingress and egress.
- Define explicit allow rules per workload, tied to identity or namespace.
- Use workload identity or mTLS to validate communication paths.
- Monitor and alert on unexpected traffic patterns (e.g., a frontend pod calling credential storage or control-plane endpoints).
Most importantly, review exposure from the outside in. What’s reachable from the internet? From your VPC? From within the cluster? Assume compromise, then verify that the next hop is blocked.
D. Automate Governance and Compliance Evidence
Security controls mean little if you can’t prove they’re working, and even less if you can’t show who owns them, how they’re enforced, and whether they’ve drifted. In enterprise environments, being secure and being able to demonstrate it are two different challenges. That’s where automated evidence and policy-backed governance come in.
Start by treating your platform posture as an auditable system of record. For every control, identity enforcement, build provenance, runtime restrictions, secret handling, there should be a corresponding policy, a proof of execution, and a way to trace that control back to an artifact or event.
That doesn’t mean manually exporting logs or dumping screenshots before a compliance review. It means wiring control validation into your CI/CD pipeline, your deploy infrastructure, and your posture system so that every action is accompanied by structured evidence, a signed SBOM, a policy result, and a risk decision.
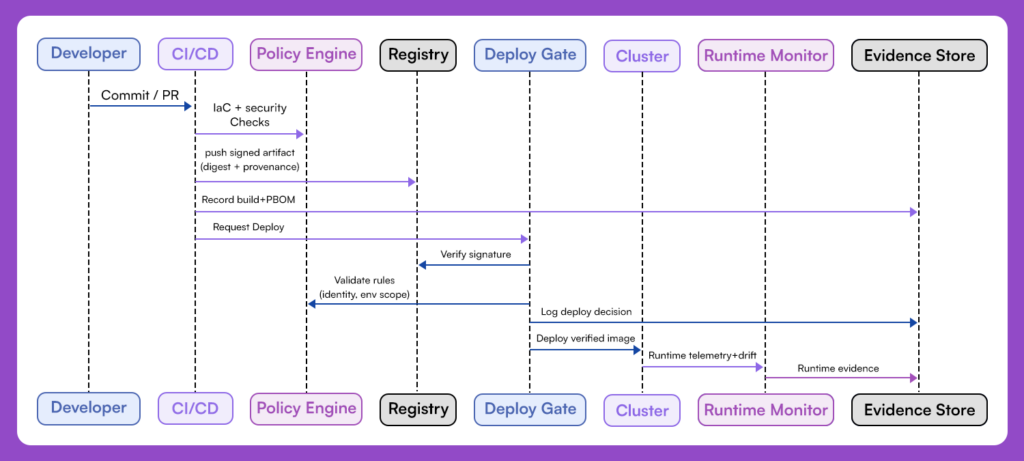
A well-instrumented platform produces:
- Signed Software and Pipeline Bill of Materials (SBOMs and PBOMs) tied to every artifact
- Audit logs that trace identity, action, time, and policy outcome
- Ownership mappings that define who is responsible for each control and its remediation
- Compliance alignment, controls mapped to frameworks like NIST 800-53, PCI-DSS, ISO 27001
The real value isn’t just ticking boxes, it’s minimizing the time to answer questions like:
- What image is running in prod, and who built it?
- Was that policy enforced at deploy time, or did it drift?
- Is this API exposed externally, and if so, what auth checks are in place?
- If a secret were leaked from this pipeline, what workloads could it affect?
In one case I reviewed, the audit window required proving that every production deploy in the last 30 days came from a reviewed pipeline, passed security gates, and included a complete SBOM. The team didn’t have to backfill; the data was already there. Each deploy event in their system included a pointer to the artifact’s PBOM, the gate status, the policy log, and the responsible team. What would’ve taken two engineers two weeks took 15 minutes.
The takeaway: automate the repetitive parts of governance so you can focus on improving real controls. Compliance should be a natural output of how your platform operates, not a parallel process that gets rushed before audits.
How Ox Establishes a Unified Code-to-Production Security Graph
Ox Security connects identity, builds integrity, network exposure, and governance into one view across your entire delivery chain, source control, CI/CD, registries, and runtime. So when something breaks or looks suspicious, you can immediately answer: What commit introduced this? Who pushed it? Where did it go? Is it still running?
This level of traceability doesn’t just help triage; it helps prioritize. You can filter static findings by runtime exploitability. You can identify which APIs are reachable and which aren’t. You can generate SBOMs and policy logs in real time, which helps you maintain control.
Here’s what that looks like when you map it across the entire SDLC, including risk, ownership, and control, in one place.
Ox’s Code-to-Runtime Graph: Mapping Risk, Ownership, and Control Across the SDLC
By the time an organization operates across multiple pipelines, registries, cloud accounts, and runtime environments, the problem is no longer scanning; it’s sustaining a coherent security posture at scale. Scanners can identify issues, but they don’t show how those issues entered the system, how they relate to identities or pipelines, or whether they create real exposure. At enterprise scale, that missing continuity becomes the real risk: it weakens governance, obscures ownership, and makes auditability reactive instead of inherent.
Ox addresses this gap by providing a code-to-runtime product security model, a single connected view across developer workflows, CI/CD pipelines, image registries, cloud resources, and live workloads. Instead of treating each stage as a separate problem, Ox correlates signals into one security fabric and uses that continuity to classify risks by exploitability, trace issues to their origin, and anchor remediation to accountable owners.
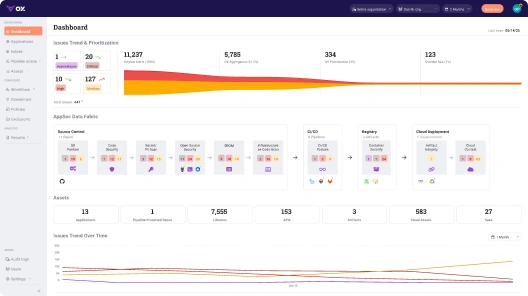
The AppSec Data Fabric shown below flags security signals across Git posture, SBOMs, OSS, IaC misconfigs, registry states, cloud context, and runtime deployments. Each stage is represented as a node in the delivery chain:
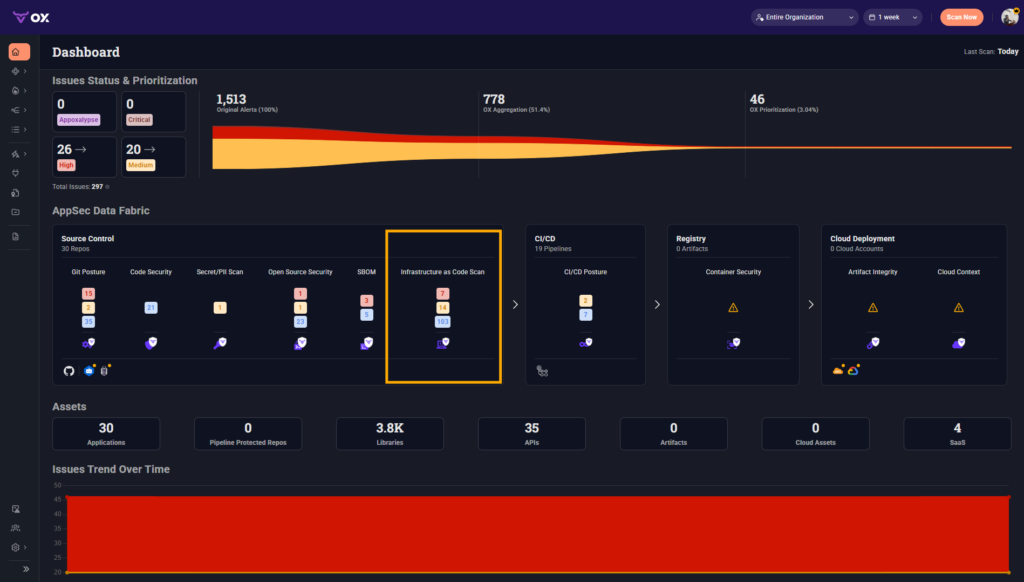
The highlighted Infrastructure as Code Scan tile is one such bridge, surfacing misconfigurations in source repositories and providing traceability across downstream systems. The platform’s main purpose is to help organizations ship secure software at scale by avoiding vulnerabilities at development speed and enabling fast, ownership-backed remediation.
In implementation, this makes Ox the connective tissue that large engineering organizations lack. It turns governance into something enforceable where risk actually enters the lifecycle, strengthens risk posture by correlating misconfigurations with real exposure paths, and generates structured evidence for audit and compliance. The goal isn’t to replace existing tools, but to give enterprises the missing map that ties code, pipelines, artifacts, cloud infrastructure, and runtime behavior into a single, explainable system.
To ground this in the practices outlined earlier, the table below shows how a code-to-runtime security model like Ox’s makes those principles enforceable across an entire organization.
| Security Practice | Enterprise Need | How Ox Enables It Systemically |
| Identity-First Controls | Clear attribution; enforceable least privilege; accountable access paths. | Ox binds workloads, pipelines, and commits to concrete identities, enabling reliable identity lineage and enforceable governance. |
| Signed Builds & Trusted Registries | Verifiable build chain; resistance to supply-chain tampering. | Ox validates SBOM/PBOM provenance and ensures only trusted, traceable artifacts move through deployment workflows. |
| Restricted Ingress & Runtime Exposure | Understanding and limiting blast radius across clouds and clusters. | Ox correlates routing, IAM roles, and runtime telemetry to reveal which workloads are actually reachable and how they could be misused. |
| Exploitability-Based Prioritization | Reduce noise; focus engineering effort on meaningful risks. | Ox ranks findings using runtime reachability, permissions, and exposure, surfacing only issues with real operational impact. |
| Runtime Drift & Behavior Monitoring | Detect deviations and tie them to accountable sources. | Ox maps anomalies (unexpected binaries, outbound calls, privilege changes) back to the pipelines and commits that introduced them. |
| Automated Governance & Evidence | Consistent, defensible audit posture without manual effort. | Ox automatically records lineage, policy outcomes, owner mappings, and artifact metadata, producing audit-ready evidence as a natural output of delivery. |
The next section walks through a real IaC finding in the prod-compute-vm repository and shows how a misconfiguration with a broad blast radius was identified, contextualized, remediated, and ultimately encoded as an enforceable organizational control.
Remediating a Project-wide SSH Key Risk in prod-compute-vm, from detection to enforcement
The prod-compute-vm Terraform repository provisions a production compute VM and exposes standard module files (main.tf, variables.tf, outputs.tf). During a routine IaC scan, Ox flagged a high-severity configuration pattern that still shows up in many real-world GCP environments: project-wide SSH keys that allow a single credential to access every VM in the project.
This pattern usually isn’t introduced intentionally. It often comes from older Terraform modules, implicit GCP metadata inheritance, or operational shortcuts carried forward over time. But in cloud-native environments, it dramatically expands the blast radius. A single compromised key becomes a fleet-wide compromise, exactly the failure mode identity-first controls are meant to eliminate.
Below is how the platform team addressed the issue end-to-end, and how Ox provided the connective tissue that made the process both fast and enforceable.
Detection & context: what Ox flagged
When the scan completed, Ox showed a misconfiguration along with the full context around it, as visible in the snapshot below:
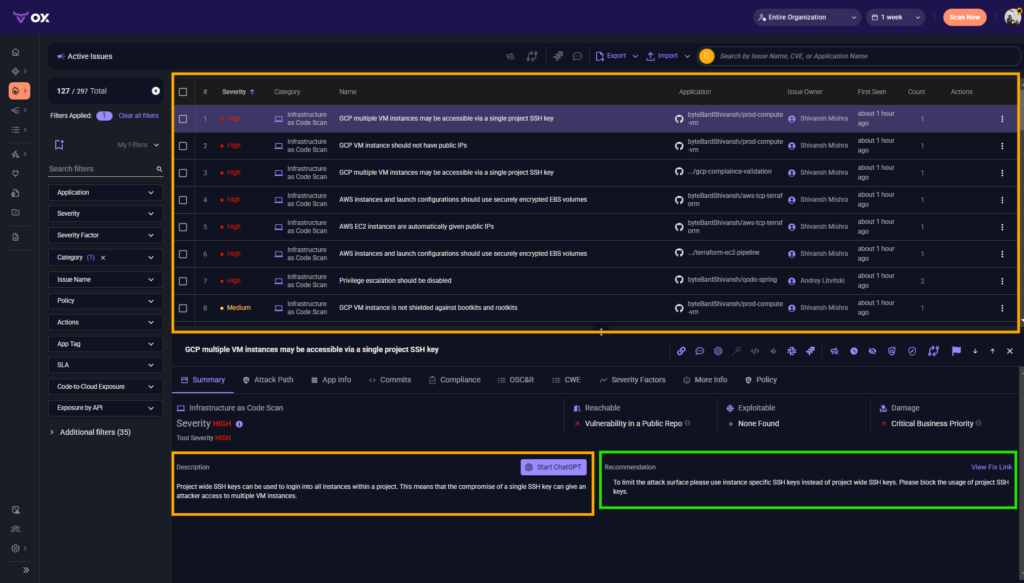
Here’s the context we get for each issue flagged as shown in the snapshot above:
- the exact repo, file, and commit that introduced the pattern,
- whether the VM was reachable from public ingress routes,
- IAM and service account permissions tied to the workload,
- remediation guidance grounded in GCP best practices (instance-level keys, OS Login),
- the owning application and the responsible team.
Crucially, Ox elevated the issue because the affected VM sat in a production boundary and was reachable through defined network paths, making the SSH key inheritance exploitable.
This directly maps to the best practices described earlier: Ox provides lineage (commit, pipeline, workload) and exploitability analysis (reachability + identity context), enabling the team to triage accurately rather than being drowned out by scanner noise.
Code fix: a minimal, safe Terraform change
The remediation itself was small, the kind of targeted correction engineering leaders prefer because it reduces the chance of regressions and keeps review cycles short.
The VM resource was updated to disable project-level key inheritance and adopt OS Login:
resource "google_compute_instance" "prod_vm" {
name = var.instance_name
machine_type = var.machine_type
metadata = merge(
lookup(var.instance_metadata, "", {}),
{
block-project-ssh-keys = "true"
enable-oslogin = "TRUE"
}
)
service_account {
email = var.vm_service_account
scopes = []
}
}This replaced a flat, shared access model with a scoped, identity-driven model tied to IAM. OS Login also ensures auditability, a key theme throughout this blog. Ox helped by pinpointing the exact lines in Terraform and mapping the misconfiguration back to the pipeline and the commit that introduced it.
Shift-left enforcement: Blocking SSH Metadata Changes
After the patch was merged, the team encoded the pattern into a deployment policy:
- deny any Terraform change that introduces project-level SSH metadata,
- require either block-project-ssh-keys = “true” or OS Login for all compute resources,
- Enforce the rule consistently at PR, CI, and promotion stages.
This turned project-wide SSH keys into an enforced control boundary rather than a manual convention. Ox enforced the policy uniformly across pipelines, minimizing dependency on manual review and institutional memory.
Verification, evidence, and end-to-end traceability
Once the fix was deployed:
- Ox re-scanned the IaC and verified that the issue was resolved.
- It attached the remediation commit, pipeline run, PBOM/SBOM, and policy decision to the workload lineage.
- The entire chain became audit-ready evidence that could be surfaced during compliance cycles without any manual work.
This is the operational advantage you emphasized earlier: governance becomes an inherent part of platform operations rather than a periodic scramble.
Operational follow-ups: making the improvement structural
To ensure long-term consistency, the team:
- baked the rule into baseline Terraform modules used org-wide,
- enabled drift detection so Ox could flag any reintroduction of project-level keys,
- aligned IAM roles so OS Login identities remained appropriately scoped,
- assigned SLA-backed ownership to any future regressions.
Ox’s scanning and runtime correlation mean that if someone attempts to reintroduce project-level SSH access in another repo, another service, or another environment, the platform team will see it immediately, with exact lineage and blast radius.
Using the CSV for scale-level remediation and governance
The CSV export of issues plays a strategic role at scale:
- It supports bulk backlog creation across multiple teams,
- It identifies systemic misconfiguration patterns rather than isolated issues,
- And when joined with Ox’s policy logs, it forms evidence bundles for auditors and internal governance.
In organizations, this is how individual findings translate into durable organizational improvements.
Conclusion: Cloud-Native Security in 2026 Requires Built-In Enforcement and Lineage
In 2026, cloud-native platforms face a new kind of risk: not just from exposed endpoints or misconfigured firewalls, but from unverified builds, overly permissive pipelines, and workloads running without clear lineage or identity. The real threat plane is the end-to-end software delivery chain, Git commits, CI jobs, container registries, infrastructure as code, and runtime behavior, all moving faster with AI-assisted development and multi-cloud complexity.
To secure this environment, platform teams need more than scanners. They need real-time enforcement on identity, artifact provenance, and deployment policy, directly within the CI/CD and runtime stack. This shift defines the foundation for resilient, scalable security in 2026. Cloud-native platforms require built-in enforcement, end-to-end traceability, and real-time context, not as enhancements, but as architectural requirements.